How to make an RSS feed for your SvelteKit blog, part 2

DALL-E 2 - "a glowing orange rss icon floating in the middle of a dark library"
I previously blogged about how to make an RSS feed for your SvelteKit blog with the full contents of every post. That way, if someone opens your post in their favorite RSS reader, they can read the whole thing without being forced to click through to your website.
However, in the two months since I wrote that post, I’ve actually improved my RSS feed quite a lot.
So, here’s how you really build an RSS feed generator in SvelteKit.
Create a server route for rss.xml
Many steps for this process have not changed. Open the old guide and follow it until you get to the subtitle “Putting content in the feed.” Stop there! If you install Showdown.js, you’ve gone too far.
Put content in the feed (in a better way)
At this point in the process, we should have getRssXml().
import {
BLOG_AUTHOR,
BLOG_AUTHOR_EMAIL,
BLOG_DESCRIPTION,
BLOG_TITLE,
BLOG_URL
} from '$lib/blog-metadata';
import { create } from 'xmlbuilder2';
// ...
// prettier-ignore
async function getRssXml(): Promise<string> {
const rssUrl = `${BLOG_URL}/rss.xml`;
const root = create({ version: '1.0', encoding: 'utf-8' })
.ele('feed', {
xmlns: 'http://www.w3.org/2005/Atom',
})
.ele('title').txt(BLOG_TITLE).up()
.ele('link', { href: BLOG_URL }).up()
.ele('link', { rel: 'self', href: rssUrl }).up()
.ele('updated').txt(new Date().toISOString()).up()
.ele('id').txt(BLOG_URL).up()
.ele('author')
.ele('name').txt(BLOG_AUTHOR).up()
.ele('email').txt(BLOG_AUTHOR_EMAIL).up()
.up()
.ele('subtitle').txt(BLOG_DESCRIPTION).up()
for await (const post of allPosts) {
const pubDate = post.metadata.date;
const postUrl = `${BLOG_URL}/blog/${post.postPath}`;
const summary = post.metadata.description;
root
.ele('entry')
.ele('title').txt(post.metadata.title).up()
.ele('link', { href: postUrl }).up()
.ele('updated').txt(pubDate).up()
.ele('id').txt(postUrl).up()
.ele('summary').txt(summary).up()
.up();
}
return root.end();
}Next, let’s add a function to the same +server.ts file called getHtmlForPost(). It’ll also be asynchronous.
import { readFile } from 'fs/promises';
// ...
async function getHtmlForPost(
postPath: string,
): Promise<string> {
const postMarkdownWithFrontmatter = await readFile(
`./posts/${postPath}.md`,
'utf-8'
);
const postMarkdown = postMarkdownWithFrontmatter
.split('---')
.slice(2)
.join('---')
.trim();
// ...I keep my blog posts in a posts folder located in the root of my project. postPath is the name of the blog post file, minus the .md extension. We use Node’s fs module to load the raw text in the file, then strip the YAML frontmatter. That leaves the post Markdown.
Parse the Markdown
To turn the Markdown into HTML, we should use the same parser as SvelteKit - remark. Run npm i -D remark remark-rehype remark-gfm to install it and some handy plugins. Add this onto the end of getHtmlForPost():
import { readFile } from 'fs/promises';
import { unified } from 'unified';
import rehypeStringify from 'rehype-stringify';
import remarkParse from 'remark-parse';
import remarkRehype from 'remark-rehype';
import remarkGfm from 'remark-gfm';
// ...
async function getHtmlForPost(
postPath: string,
): Promise<string> {
const postMarkdownWithFrontmatter = await readFile(
`./posts/${postPath}.md`,
'utf-8'
);
const postMarkdown = postMarkdownWithFrontmatter
.split('---')
.slice(2)
.join('---')
.trim();
const processedMarkdown = await unified()
.use(remarkParse) // <- Parses markdown
.use(remarkRehype) // <- Converts Markdown to HTML
.use(rehypeStringify) // <- Serializes Markdown 🤷♂️
.use(remarkGfm) // <- Supports footnotes, code blocks
.process(postMarkdown);
let postHtml = processedMarkdown.toString();
// ...The Markdown has been parsed!
Encode HTML tags in code examples
If, like me, you use HTML code snippets in your blog posts, RSS readers will think they are real HTML and try to render them (see the original guide for more).
Suffice to say we should escape HTML code snippets to avoid rendering errors.
// ...
postHtml = postHtml.replaceAll('<', '&lt;');Fix broken image links
At this point, if you preview your post in an RSS reader and it has inline images, the images will 404.
To fix this, run npm i -D jsdom. We’ll use jsdom to create a virtual HTML document and make updates without ugly string editing.
import { base } from '$app/paths';
import { JSDOM } from 'jsdom';
// ...
postHtml = postHtml.replaceAll('<', '&lt;');
const postDom = new JSDOM();
postDom.window.document.body.innerHTML = postHtml;
addBasePrefixToImages(postDom);
// ...
function addBasePrefixToImages(dom: JSDOM): void {
const allImages = Array.from(
dom.window.document.getElementsByTagName('img')
) as HTMLImageElement[];
allImages.forEach(image => {
const src = image.getAttribute('src');
if (src) {
// My blog's images are stored in /static/img
// Your image path may be different
image.setAttribute('src', `${base}/img/${src}`);
}
});
}addBasePrefixToImages() iterates through each <img> in your post and prefixes its src to include base, the base path your app is served on.
Remove the bad base prefix
When I write a link to another blog post, I put:
[my AI post]({base}/blog/ai-browser-extension)When Svelte compiles the site for the web, it converts {base} into the base prefix, the path the site is served on.
However, when we created postHtml with remark, remark left these {base} references alone. The link above, when compiled by remark, looks like:
<a href="{base}/blog/ai-browser-extension">my AI post</a>…which 404s. Let’s remove those {base} prefixes from our HTML.
// ...
addBasePrefixToImages(postDom);
removeBasePrefixFromElements(postDom);
// ...
function removeBasePrefixFromElements(dom: JSDOM): void {
const basePrefix = '{base}';
const encodedBasePrefix = encodeURIComponent(basePrefix);
const allElements = Array.from(dom.window.document.getElementsByTagName('*'));
allElements.forEach(element => {
const href = element.getAttribute('href');
if (href?.startsWith(basePrefix)) {
element.setAttribute('href', href.slice(basePrefix.length));
}
if (href?.startsWith(encodedBasePrefix)) {
element.setAttribute('href', href.slice(encodedBasePrefix.length));
}
const src = element.getAttribute('src');
if (src?.startsWith(basePrefix)) {
element.setAttribute('src', src.slice(basePrefix.length));
}
if (src?.startsWith(encodedBasePrefix)) {
element.setAttribute('src', src.slice(encodedBasePrefix.length));
}
});
}Make your footnotes RSS-ready
The last super fiddly bit of HTML fixing we need is around footnotes. A properly rendered footnote will appear as a link on the web and as an inline button in RSS readers like NetNewsWire.
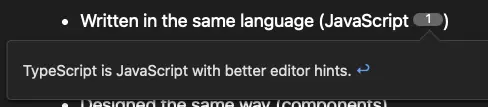
Incorrectly rendered footnotes will appear as links in the RSS reader and bounce your audience to the web version of your post. Even worse, they may not even link to the right footnote!
Here’s how to fix it:
// ...
addBasePrefixToImages(postDom);
removeBasePrefixFromElements(postDom);
inlineFootnotes(postDom);
// ...
function inlineFootnotes(dom: JSDOM): void {
const footnoteLinkPrefix = '#user-content-fn-';
const prefixToRemove = '#user-content-';
const allLinks = Array.from(dom.window.document.getElementsByTagName('a'));
allLinks.forEach(link => {
const href = link.getAttribute('href');
if (href?.startsWith(footnoteLinkPrefix)) {
const newFootnoteHref = '#' + href.slice(prefixToRemove.length);
const footnoteContentElem = dom.window.document.getElementById(
href.slice(1)
) as HTMLLIElement | null;
footnoteContentElem?.setAttribute('id', newFootnoteHref.slice(1));
link.setAttribute('href', newFootnoteHref);
}
});
}This function iterates your links, checks if they’re footnotes, and makes sure the element it links to has the right id. For whatever reason, this is the id naming scheme that makes footnotes display inside RSS readers 🤷♂️.
Add the lead image
If I put image or caption in the YAML frontmatter of a blog post, that image appears as the lead image on the web version of the post. It also appears as the post image when shared on social media.
I’d like that image to appear in the RSS feed too.
// ...
async function getHtmlForPost(
postPath: string,
leadImageFilename?: string,
leadImageCaption?: string
): Promise<string> {
// ...
if (leadImageFilename) {
const leadImage = postDom.window.document.createElement('img');
leadImage.src = `${base}/img/${leadImageFilename}`;
if (leadImageCaption) {
const caption = postDom.window.document.createElement('caption');
caption.textContent = leadImageCaption;
postDom.window.document.body.prepend(caption);
}
postDom.window.document.body.prepend(leadImage);
}
return postDom.window.document.body.innerHTML;
}
// ...And that’s it!
Conclusion
I’ve uploaded the full RSS +server.ts file to GitHub. Let me know if there are any improvements I could make!